Search Posts
人机协作编程与 Prompt 设计
发布者:z1m
(因为会的东西不太多,最近一直在vibe coding,所以就(水)发一篇这方面的博客(雾
人机协作的三种实用模式
日常写代码时,AI 并不是只有一种用法。根据任务复杂度,我们可以把协作方式分成三类,每类都有自己最舒服的使用场景。
代码补全更像是智能联想输入,你写一半,它帮你补完剩下的。
工具代表:GitHub Copilot、Tabnine
适合场景:样板代码、简单逻辑、API 调用、重复结构
特点:轻量、无感、随写随补,不用打断思路
平时敲代码时,它会默默根据上下文给出建议,是最基础也最常用的辅助方式。
对话式生成相当于身边坐着一个随时能聊的编程搭档,你用自然语言描述需求,它直接给出完整方案。
工具代表:Cursor Chat、ChatGPT、Claude 3.5
适合场景:算法实现、架构思路、代码重构、找 Bug、优化性能
特点:可以多轮沟通、慢慢调整、理解复杂意图
遇到难搞的逻辑时,这种方式最省心,你说清楚需求,它帮你把骨架搭好。
自主智能体模式更像一个能独立干活的 “数字实习生”,给一个目标,它自己规划、写代码、运行、调试、改错。
工具代表:Devin、OpenDevin、MetaGPT
适合场景:完整小功能开发、仓库级批量修改、自动修复问题
特点:几乎不用人工盯守,自主闭环完成任务
这种模式还在快速发展,但已经能处理不少端到端的开发任务。
工具项目理解能力环境联动最擅长的事Cursor很强,能读整个项目可直接跑终端项目重构、全库分析GitHub Copilot中等,文件级较弱行级补全、语法纠错Claude 3.5中等,靠粘贴 / 附件可预览结果算法推导、逻辑严谨DeepSeek Coder较弱无中文友好、轻量脚本
LLM 核心机制:从代码视角看懂大模型
不用啃晦涩论文,我们用更轻松的方式,理解大模型 “为什么能写代码”。
大模型到底在做什么?核心其实很简单:根据前面的内容,预测下一个词(token)出现的概率。
可以理解成:超级无敌加长版的完形填空。
它靠海量文本和代码,学到了语法、结构、逻辑、规律,最后能生成连贯合理的内容。
能力涌现:模型变大后突然 “变聪明”
当模型参数量达到一定级别(一般认为 >10B),会突然在很多任务上表现飞跃:
- 复杂推理变稳
- 代码结构更规范
- 能理解多轮意图
- 少量示例就能模仿风格
这种现象就叫能力涌现,也是大模型能真正用于编程的基础。
大模型的三步训练流程
你可以把训练理解成 “教模型做事” 的过程:
预训练:海量阅读,学知识、语法、代码结构
指令微调:学会听懂人类的指令,知道该怎么响应
RLHF 人类反馈强化学习:按人类偏好排序,让输出更有用、更安全、更靠谱
三步走完,模型就从 “只会填空” 变成了 “能干活的助手”。
AI Agent 是怎么跑起来的?
智能体的工作流非常清晰:
任务 → 思考规划 → 调用工具 → 观察结果 → 循环调整 → 完成
它可以:
-
读写文件
-
执行命令
-
分析报错
-
自动修复
一步步把复杂任务自己跑完。
Prompt 设计:写出好用的工程级指令
Prompt 不是随便提问,而是用自然语言给 AI 一份清晰的需求文档。写得好,代码质量直接起飞。
一个好 Prompt 必备三要素
想让 AI 输出工程可用的代码,这三点一定要写全:
角色 / 背景(Context)
告诉 AI 你的技术栈、版本、环境、项目结构,减少它 “瞎猜” 和幻觉。
任务目标(Task)
用明确的动作描述,比如:实现、重构、优化、调试、写测试。
越具体,结果越准。
约束规则(Constraints)
规定好:复杂度、性能、内存、规范、安全、异常处理等。
相当于给 AI 划定 “不能踩的线”。
超实用的 CO‑STAR 框架
日常写 Prompt 可以直接套这个结构,特别稳:
- C(Context):技术背景、环境、依赖
- O(Objective):要实现什么功能
- S(Style):代码风格、注释、异步 / 同步
- T(Tone):简洁风 / 教学风 / 工程风
- A(Audience):给谁用(新手 / 架构师 / 评审)
- R(Response):输出格式(代码块 / JSON / 文档)
几个比较好用的高阶 Prompt 技巧
Few-shot 少样本提示
给 AI 看一两个你喜欢的代码示例,它就能自动模仿你的风格:命名、注释、错误处理、结构全都对齐。
CoT 思维链
遇到复杂算法,别让它直接写代码。
让它先分析需求、讲算法思路、写伪代码、列边界条件,最后再输出代码。
准确率会明显更高。
分而治之
大需求别一次丢给 AI,拆成小步骤:
设计结构 → 定义基类 → 实现接口 → 补全逻辑 → 加测试
逻辑更清晰,也更容易修正。
测试驱动 Prompt(TDD)
先让 AI 写测试用例,覆盖正常、空值、异常、极值场景,再让它写业务代码。
这样能大幅降低 AI 幻觉,逻辑更稳。
自我审查
让 AI 自己检查自己的代码:
- 复杂度是否合理
- 有没有边界问题
- 有无内存 / 句柄风险
- 是否符合规范
- 有没有安全隐患
相当于多了一层自动保障。
一些坑
- 别用否定句:比如 “不要用递归”,换成 “请用循环实现”
- 别用模糊形容词:“高性能”→ 明确写 O (n log n)、内存限制等
- 别把一堆要求堆在一起:拆分优先级,核心逻辑优先
- 别写一整段长句:分段、加标题,AI 更容易读懂
创意编程赛
发布者:SuperKenVery
创意编程赛马上要上线啦!
规则与样例:文档
三省六部Agent架构:探讨"虚拟公司"式多Agent架构在工程上是否成立
发布者:Xavier
什么是“三省六部”式架构
这个比喻指的是一类在社区里广泛流行的多 Agent 设计思路,在不同框架和文章里有不同名字:role-based agents、virtual team、CrewAI 式分工、MetaGPT 式组织——本文统称“三省六部”。
它的核心模式是:把一个复杂任务拆解成若干职能,每个 Agent 扮演一个角色:如 PM 负责需求,Dev 负责实现,QA 负责测试。任务以流水线形式在 Agent 之间流转。这个模式在图示上非常好看。它满足了人类对“分工协作”的直觉,也让“AI 团队”这个概念变得具象、可解释。
问题不在有没有 PM Agent、QA Agent 这样的标签,而在于任务边界是不是按职能角色来切,信息是不是以压缩摘要的形式在角色之间单向接棒。前者只是命名,后者才是机制。
这不免让人产生一种直觉:任务流程经过这样的拆分重建之后,往往会更容易被 Agent 执行。可事实果真如此吗?
“三省六部”式分工在Agent世界里真的成立吗
人类需要分工,是因为:
- 单个人的注意力有限,无法同时处理所有信息
- 人有专业壁垒,社会演进产生了社会分工
- 人与人之间需要接口来协调
但 LLM 的特性并不完全对应这套逻辑:
- 同一个模型既能写 PRD,也能写代码,并没有天然的“职业边界”
- 模型的瓶颈通常不是“它属于哪个岗位”,而是推理深度、信息完整性和目标连续性
- 模型之间也没有人类组织里那种默认存在的文化、默契和非正式沟通,无法自然补偿信息损耗
给 Agent 贴上“产品经理”的标签,不会自动让它更专业;很多时候只是把人类组织里的边界投射到了模型系统里。一个被框死在“测试工程师”角色里的 Agent,看到架构层的问题,完全可能直接跳过,因为“这不在我的职责范围内”。而最有价值的推理,恰恰经常发生在边界上。
如果任务必须拆分,拆分维度更接近信息维度,而不是岗位维度。按代码、设计、测试、模块边界、搜索方向、上下文隔离来拆,和按 PM、Dev、QA 来拆,不是一回事。前者在处理信息依赖,后者在复刻人类组织习惯。
Cosplay不是原罪,但用角色来决定信息边界是。
信息在流转中死亡
三省六部模式里,Agent A 产出一个文档,传给 Agent B。
问题不在于“有文档”,而在于这个过程中传递的往往是结论摘要,不是原始材料,更不是完整的推理上下文。
B 拿到摘要后,需要基于 A 的理解版本重新建立上下文。原始意图在衰减,隐含假设在丢失,每次传递都在累积误差。工作流越长,最终输出就越容易变成“局部正确但整体漂移”——每个节点看起来都合理,但系统整体已经偏离了最初的目标。
人类组织可以靠会议、文化、非正式沟通去补偿这些损耗。Agent 之间没有这些机制。
分水岭不在有没有多 Agent,也不在有没有角色标签,而在于下一个执行节点拿到的是原文,还是转述。
同样是一个“Developer Agent”,有两种完全不同的做法:
- 一种是给它product-spec.md的路径,让它自己去读原文
- 另一种是给它一段由主 Agent 改写过的需求描述,让它按这个实现
两者在架构图上长得几乎一样,但结果完全可能不是一回事。前者读的是 source of truth,后者继承的是上游的理解版本。前者还有重新判断的空间,后者在结构上已经埋下了信息失真的种子。
与其说问题在“传结论不传推理”,不如说问题在于:信息流转时,传过去的是原文,还是摘要。
为什么外部状态文件和“三省六部式交接”不是一回事
这里有一个常见反驳:三家厂商的解法里,progress.txt、spec 文件、runbook 不也是“传文件”吗?区别在哪?
区别不在“有没有文件”,而在于这个文件到底在做什么。
三省六部的信息流转,本质上是角色间的单向交接:A 写完交给 B,B 基本不再回头,A 也不知道 B 具体怎么使用这份材料。信息被压缩成一个便于接棒的结果,推理过程在交接点被截断。
外部状态文件更像是同一任务的显式持久化状态:它记录的是任务的正式历史、关键约束、当前进度和运行规则。后续执行者读取的不是某个“同事”的转述,而是这个任务自己的 source of truth 和 checkpoint。
这个区别决定了推理链能不能跨 session 保持连续。
大量 token 被浪费在 Agent 之间的“交接文件”上,而不是用于实际推理。你得到的往往是一个模拟公司行为的系统,而不是一个真正围绕问题本身组织起来的系统。
御三家实际怎么做的
值得注意的是,当 Anthropic、OpenAI、Google 真正构建自己的生产级 Agent 系统时,他们的工程文档里几乎看不到“部门分工”式的核心设计逻辑。
Anthropic:Context Engineering + 显式状态文件
Anthropic 内部把“Prompt Engineering”升级成了“Context Engineering”:问题不是怎么写一个漂亮 prompt,而是什么样的 token 配置最能稳定地产生想要的行为。
在构建 Claude Code 和 Research 系统时,他们面对的核心挑战是:Agent 必须在离散的 session 中工作,每个新 session 对之前发生的事情没有天然记忆。
他们的解法不是让多个“岗位 Agent”流水线接棒,而是:
- 用 progress / runbook 一类文件保存任务连续性
- 用 Git history 作为状态锚点
- 用 initializer 或 orchestrator 建立统一的任务上下文
- 让 subagent 并行探索,再把结果回流给主 Agent 综合
关键洞察是:推理链的连续性不靠模型“记住”,靠显式的外部状态来锚定。
他们同时发现,把某一代模型的行为特征硬编码进 harness 是危险的。某个版本的模型可能会在快到 context limit 时提前收尾,于是工程上加了 context reset;下一代模型这个问题消失了,原来的补丁反而变成了负担。这说明 harness 必须跟着模型演化,所谓“永久解法”,很多时候只是当前阶段的工程妥协。
在多 Agent 的 Research 系统里,Anthropic 的架构是 orchestrator-worker:一个 lead agent 负责分解任务、协调 subagent,subagent 并行探索不同方向,结果再回流给 lead agent 综合。他们发现 token 消耗量本身就解释了相当大一部分性能差异——多 Agent 的价值不在于“角色分工更像公司”,而在于用更多 token 覆盖更大的搜索空间。
Anthropic 的 subagent 看起来也像“分工”,但和三省六部不是一回事。三省六部是职能性串行分工——不同角色做不同工种,PM 做完传给 Dev,Dev 做完传给 QA。Anthropic 的 subagent 更接近功能性并行探索——多个 agent 同时搜索不同方向,没有“下一棒”,结果统一汇聚回同一个 orchestrator 综合。前者是接力赛,后者是同时撒网。
OpenAI:Compaction + Skills + 结构化 Spec 文件
OpenAI 给出的长任务原则更直接:在任务开始时就为 continuity 做规划。
在 Codex 的实验里,工程师会先给 agent 一个 spec 文件,冻结目标,防止 agent 做出“看起来很厉害但方向错了”的东西;再让它生成 milestone-based plan,用 runbook 维护长任务中的过程状态。
结果是,模型可以连续运行很长时间,仍然保持任务连贯性。
这里最重要的不是“多个角色协作”,而是:
- 目标被结构化固定
- 状态被持久化记录
- 连续线程通过 compaction 和 previous_response_id 维持
- Skills 提供的是稳定的操作规范,不是岗位身份
Skills 是工具化的操作经验,不是角色扮演。
这和“先让 PM Agent 写文档,再让 Dev Agent 接棒”是两套思路。
Google:大上下文 + 持久化项目意图
Google 的路线看起来是硬扩窗口:Gemini 的大上下文确实减少了很多传统 RAG 切片和消息丢弃带来的问题。
但他们自己的工程实践也没有停留在“把一切都塞进聊天窗口”这一层。Google 也在通过持久化的 spec / plan 文件,把项目意图从易漂移的聊天记录里抽离出来。
这说明即使窗口足够大,正式任务依然需要外部锚点。
大上下文不能替代结构化的任务状态管理。
真正的架构原则是什么
从三家的工程实践里,更能提炼出的是下面这些原则,而不是“模拟一个公司组织结构”。
推理链不能被串行接棒切断,只能分叉再合并。
多 Agent 的合理用法不是流水线交接,而是主 Agent 持有完整意图,子调用去探索子问题,结果再回流合并。
显式外部状态,不靠模型记住。
progress.txt、spec、runbook、git history、数据库,形式不重要;原则是关键状态必须落地。
多 Agent 的价值首先是并行覆盖和上下文隔离,不是职能分工。
Anthropic 的经验说明,多 Agent 的收益很大程度来自更大的搜索覆盖。除此之外,多 Agent 还有一个常被忽略但非常合理的用途:隔离不同任务的上下文,防止污染。
比如同时跑多个并行 feature、多个独立调研线程、多个不应互相干扰的子问题。这时多 Agent 的意义不是“谁负责什么岗位”,而是“谁拥有哪一块独立上下文”。
验证 Agent 是否定者,不是接棒者。
如果要做质量控制,合理方式是让一个 Agent 去找另一个 Agent 的问题,而不是顺着上一个 Agent 的摘要继续往下做。对抗性检验,不是流水线传递。
工具是工具,不是角色。
给 Agent 配什么工具,远比给它贴什么岗位名重要。工具决定它能做什么;角色标签很多时候只是限制它“以为自己该做什么”。
能用工具解决的,就不要用 Agent 解决。
如果一个子任务的边界明确、输入输出清晰、行为可预期、可以稳定封装,那它更适合做成工具,而不是一个“某某 Agent”。因为工具通常更快、更稳、更省 token,也更容易测试和调试。
多 Agent 更适合那些边界无法预先完全写死、需要自主探索、需要并行覆盖,或者确实需要上下文隔离的场景。其他情况,工具往往是更好的答案。
三省六部为什么会流行
因为它太符合人类直觉了。
“这个 Agent 是 PM,那个是 QA。”
这句话几乎不需要解释。它天然满足人类对“AI 像团队一样工作”的想象,也很容易向管理者、产品经理和非技术受众展示。
它还很好画图:有角色、有部门、有箭头、有交接,非常直观。
但好解释、好展示,不等于在工程上最合理。
真正决定效果的,不是这张图讲得多顺,而是信息到底怎么拆、怎么传、怎么合。
更深层的原因是:很多采用这个模式的团队,并没有真正被“多 Agent 之间的信息损耗”反复打过脸。任务复杂度不够时,问题可能被其他因素掩盖;一旦复杂度上来,系统开始出现那种诡异的“局部正确、整体错误”,这个问题就会暴露出来。
结语
最好的多 Agent 系统,不像公司。它更像一个思考过程的多次展开——同一个问题在不同方向上被并行探索,最后再回到同一个意图中心,收束成一个连贯的结论。
从这个原则出发:
不要问“我需要几个 Agent”,要问“这个任务的信息依赖结构是什么”。
如果任务需要连续推理、上下文高度依赖,比如写一个复杂功能的设计文档,单 Agent + 好的 context engineering 通常优于多 Agent 流水线。
如果任务需要同时探索多个相对独立的方向,比如同时研究 10 个竞品的不同模块,多 Agent 并行就是合理的。每个 subagent 的任务彼此独立,信息损耗代价最小;它的价值来自更大的搜索覆盖,或者更干净的上下文隔离,而不是来自“分工更像一个组织”。
问题不在有没有角色标签,而在信息流转时传的是原文还是摘要;不在是不是多 Agent,而在这个系统究竟是在分叉合并,还是在串行接棒。
Ref:https://github.com/cft0808/edict
[@sujingshen, X post](https://x.com/sujingshen)
打破继承的迷思:为什么我们应该在大多数时候拥抱“组合”?
发布者:GroundhogZ
在学习面向对象编程(OOP)的第一天,我们大概率都会接触到一个词:继承(Inheritance)。教科书里总是用“狗继承自动物”、“汽车继承自交通工具”这样完美的现实映射来向我们展示继承的美妙:代码复用、层级清晰。
然而,当我们在真实复杂的业务工程中摸爬打过后,往往会发现那些曾经引以为傲的深层继承树,最终都变成了难以维护的“焦油坑”。在现代软件设计中,一个越来越被推崇的原则是:多用组合(Composition),少用继承。
今天,我们就来深入探讨一下继承与组合的区别,以及为什么我认为组合应当在大部分日常开发中替代继承,而继承只应退守到诸如 GUI 窗口管理等极少数特定的场景中。
1. 概念重温:“是一个” vs “有一个”
在深入对比之前,我们先用最通俗的话总结两者的本质区别:
- 继承(Inheritance)代表“是一个(Is-a)”的关系。比如,
麻雀继承自鸟。这意味着麻雀拥有鸟的一切特征,它是鸟的一种特化。继承在编译时就确定了,是一种强耦合的静态关系。 - 组合(Composition)代表“有一个(Has-a)”或“用到(Uses-a)”的关系。比如,
汽车包含发动机和轮胎。汽车不是发动机,但它通过将其组装在一起实现了行驶的功能。组合在运行时可以动态改变,是一种松耦合的关系。
2. 继承的“宗罪”:为什么我们越来越怕用 extends?
不可否认,继承的初衷是为了代码复用,但在实际演进中,它暴露出了几个致命的弱点:
-
脆弱的基类问题(Fragile Base Class): 这是继承最让人头疼的地方。子类与父类是紧耦合的。如果你修改了父类中的一个基础方法,可能会在不知不觉中破坏几十个甚至上百个子类的行为。牵一发而动全身。
-
深层级的噩梦: 业务初期,“基类 -> 派生类A -> 派生类B” 看起来很合理。但随着业务膨胀,为了复用某些细枝末节的功能,继承树会变得异常臃肿。你为了引入一个功能,不得不继承一大堆不需要的代码。
正如 Erlang 之父 Joe Armstrong 曾有一句名言:“面向对象语言的问题在于,它们总是隐性地携带所有周围的环境。你只想要一根香蕉,但你最后得到的是一只拿着香蕉的大猩猩,以及整个丛林。”
-
缺乏运行时的灵活性: 继承关系在代码写完(编译阶段)就被焊死了。如果一个对象在运行时需要改变行为(比如动态切换算法),继承是无能为力的。
3. 组合的崛起:把乐高积木交还给开发者
组合之所以能成为现代架构设计(如 Go、Rust 等语言甚至直接弱化或抛弃了传统继承)的宠儿,正是因为它完美避开了上述雷区:
- 极致的松耦合: 组件之间通过接口(Interface)或协议进行通信,互不干涉内部实现。修改一个
Engine类,只要它依然满足原有的接口约束,就不会影响到包含它的Car类。 - 按需组装,拒绝臃肿: 你需要什么能力,就“注入(Inject)”或者“包含”什么组件。不需要吃下整个“丛林”,只需拿走你要的“香蕉”。
- 极高的可测试性: 面对组合模式的代码,我们可以非常轻松地通过 Mock(模拟)各个独立的组件来进行单元测试,而不需要像测试继承树那样去初始化一堆复杂的父类依赖。
在绝大多数业务逻辑、服务层设计、数据流转中,组合不仅能满足代码复用的需求,更能保证系统的弹性和可维护性。
4. 继承的“避风港”:它真的毫无用处了吗?
既然组合这么好,我们是不是该彻底把 extends 扫进历史的垃圾堆?
答案是否定的。 这也是我想强调的核心观点:继承并非一无是处,它只是被滥用了。在某些极度契合“Is-a”语义,且有着严格分类学边界的场景下,继承依然是无可替代的。
最典型的例子就是 GUI 框架和窗口管理系统。
无论是在传统的桌面应用(如 Qt, WPF, Java Swing),还是在早期的前端框架中,UI 组件的设计简直是为继承量身定制的:
- 完美的本体论映射:
Button(按钮)、TextBox(文本框)、Slider(滑块)在本质上就是一个Widget(控件)或View(视图)。这种“Is-a”关系在现实中也是绝对成立且不可辩驳的。 - 共享深层次的底层抽象: 所有的窗口控件都需要处理事件分发(点击、悬浮)、坐标计算(X/Y 轴、宽高)、渲染生命周期(Draw, Paint)、焦点管理等。这些基础行为高度一致且极其复杂。通过一个基类
BaseWindow来统一实现这些底层逻辑,让子类只关注自己的特殊绘制,是最高效的设计。 - 多态的天然舞台: 窗口管理器(如操作系统的渲染引擎)只需要维护一个
List<Widget>,并在每一帧循环调用它们的render()方法即可。它不需要知道这具体是个按钮还是个下拉菜单。
在这种领域模型极其稳定、分类学严谨且底层行为需要被高度统一管理的场景下,继承展示了它强大的统治力。强行在这里使用组合,反而会导致大量的模板代码(Boilerplate code)和繁琐的事件委托。
结语
在软件工程中,没有银弹。
当我们面对多变的业务逻辑、需要灵活插拔的服务模块时,请在敲下 extends 之前三思,问问自己能不能用组合和接口来实现。将多用组合,少用继承作为默认准则,你的代码将更具韧性。
但同时,我们也应当尊重继承在经典领域(如 GUI 框架)中不可磨灭的价值。真正的架构智慧,不在于盲目站队,更不在于对某种技术产生宗教般的狂热,而在于为每一种范式找到最适合它生长的土壤。
对有序列表的test(这个有序列表好像不起作用,疑似bug)
发布者:raccoon
- 第一点
- 第二点
- 第三点
(上述三行本应存在数字标号,但是实际并未存在)
- 第一点
- 第二点
- 第三点
一个QM-Algorithm的诞生过程
发布者:raccoon
一个QM-Algorithm的诞生过程
由于笨人水平有限,今天来 水 写一篇QM-Algorithm的编写过程。
1.问题背景(什么是QM-Algorithm?)
QM-Algorithm(Quine-McCluskey Algorithm,奎因 - 麦克拉斯基算法),是在布尔代数中用于化简布尔函数的系统方法,比卡诺图更适合多变量(通常 4 个及以上变量)布尔函数的化简,是数字逻辑电路设计中的核心工具。
核心定义与用途
QM 算法是一种系统化、可机械化的布尔函数最小化方法,通过逐步合并具有相同变量但相反取值的最小项(或最大项),消去冗余变量,最终得到布尔函数的最简与-或表达式(或者 或-与表达式),广泛应用于数字电路设计、逻辑化简等场景,可手动计算,也可通过程序实现自动化化简。
核心步骤(简化版)
- 列出布尔函数的所有最小项(或最大项),按其中 “1” 的个数分组(例如 3 变量函数,最小项 000 含 0 个 1,001 含 1 个 1,依次分组)。
- 逐步合并相邻组的最小项:若两个最小项仅一个变量取值不同(其余变量完全一致),则合并为一项,消去该不同变量(例如 AB¬C 与 ABC 合并为 AB),标记已合并的最小项。
- 重复合并步骤:对合并后得到的新项,再次按 “1” 的个数分组,继续合并相邻项,直至无法再合并(得到 “素项”)。
- 筛选必要素项:从所有素项中,筛选出能覆盖所有原始最小项的最少素项组合,即为布尔函数的最简表达式。
关键特点
- 优势:不依赖图形(区别于卡诺图),逻辑严谨、步骤固定,可处理多变量(如 5 变量、6 变量)布尔函数,适合自动化计算。
- 不足:手动计算时,变量越多,步骤越繁琐,容易出错,适合变量数量较多、卡诺图无法高效化简的场景。
卡诺图作为化简布尔代数函数的基石方法,尽管有其可视化强(图形方法)、速度快、错误率低等一系列优点,但在处理变量大于4的布尔函数时可视化程度迅速降低。其核心原因是格雷码相邻两数只相差一位二进制码的特性不再易于观察,以及高维图形的直观性较差。同时,自动化化简布尔函数的工业要求也冲击了卡诺图的使用范围。如何寻找质蕴含项和实质蕴含项很难用机器易于理解的编程语言实现,这也阻碍了机器通过机械化重复步骤实现多变量函数的快速化简。
在这种情况下,不依赖图形化、操作步骤具有可重复性的QM-Algorithm成为了工业化化简布尔函数的首选方法。
注:尽管QM-Algorithm的核心操作具有可重复性,但是在人工使用QM-Algorithm化简时非常容易发生错误,且操作步数随着变量的增加指数级提升。这导致了人工化简的时长高达卡诺图化简相同变量数布尔函数的3-4倍。
2.编程框架(数据结构的构造)
本算法由C++实现。C++支持OOP,故使用类和对象构建算法中的数据结构Minterm(最小项布尔代数式)和MergedTerm(算法合并过程中产生的已合并的布尔代数式)。同时将QM-Algorithm的4步核心步骤以及相关辅助函数封装在一个名为QMAlgorithm的类中,定义算法执行函数QMAlgorithm::run()以顺序执行调用核心步骤对应成员函数。
Minterm数据结构构造:
class Minterm {
friend class QMAlgorithm;
int dec_value; // 十进制值
int binary[MAX_BIN_BITS]; // MAX_BIN_BITS位二进制
bool is_used; // 是否被合并
bool is_dont_care; // 是否为无关项
void decimal_binary(int num,int *binary);
public:
Minterm(int dec=0, bool dc=false);
};
- 将该类设置为QMAlgorithm类的友元,方便访问。
- 设置对应类型变量存储十进制、二进制值。
- 由于QM-Algorithm支持输入无关项dont_care辅助化简布尔代数式,而无关项最终可不被包括在化简完成的布尔代数式中,故Minterm中设置bool型成员变量is_dont_care判断该项最小项是否一定需要被覆盖。
- decimal_binary函数为十进制/二进制转换函数,用于辅助Minterm对象初始化。
MergedTerm数据结构构造:
class MergedTerm {
friend class QMAlgorithm;
int merged_bin[MAX_BIN_BITS]; // 合并后的二进制串(如1-0----...)(-用2表示)
set<int> covered_minterms; // 覆盖的最小项集合
bool is_essential; // 是否为实质蕴涵项
public:
MergedTerm();
MergedTerm(const int* bin, const set<int>& mins);
};
- MergedTerm构造方式与Minterm类似。
- 由于合并最小项后某些二进制位存在缺省(同时存在1和0),使用2表示该位缺省,使得合并后的二进制串仍然可以用int型数组存储。(注:此处也可选择引入<string>头文件用string类对象存储二进制串)
- MergedTerm存储的最小项以其对应十进制数形式存储。
QMAlgorithm数据结构构造:
class QMAlgorithm {
vector<Minterm> minterms_; // 原始最小项列表(含无关项)
vector<MergedTerm> merged_terms_; // 合并后的项列表
vector<MergedTerm> essential_terms_; // 实质蕴涵项列表
set<int> required_minterms_; // 需要覆盖的最小项(不含无关项)
void mergeMinterms(); // 合并相邻最小项
int isOneBitDiff(const int* bin1, const int* bin2) const; // 判断相邻最小项
void findEssentialTerms(); // 寻找实质蕴涵项
void printTerm(const int* merged_bin) const; // 打印项
bool areTermsEqual(const int* bin1, const int* bin2) const;
public:
QMAlgorithm(const vector<int>& minterms, const vector<int>& dont_cares);
void run(); // 执行QM算法的主流程
void printResult() const; // 打印最简布尔表达式
};
- 引入<vector>头文件,使用vector存储最小项和合并项作为QMAlgorithm类的成员
- 定义合并相邻最小项、判断相邻最小项、寻找实质蕴涵项、打印项的四个主要步骤函数,用于对外接口run()调用
- 定义对外接口printResult()用于打印化简结果。
3.编写过程
整个编写过程基本都是机械化操作,只需要按照核心步骤编写即可。
- QMAlgorithm的主要成员函数基本都是对存储在vector中的最小项列表、合并项列表、实质蕴含项列表和需要覆盖最小项列表进行传递、增添和删除操作。
- 在列表中增添新项前记得进行重复项检验操作,防止vector中存入重复值。
4.关于vibe coding
由于笨人实力有限,在编写过程中遇到了一堆疑难和bug(哭)。
对于新手,我认为AI Assistance是很有必要的。但是AI不应该完全替代你在编程中的主导地位。死磕困难也是不可取的,因为不会的知识、语法,很难随便灵机一动便习得。
以笨人编写该程序的经验为例:笨人对<vector>是什么作用的略有耳闻,但到底怎么使用这个内置的类笨人知之甚少。因此在面临不知道使用什么数据类型存储Minterm、MergedTerm等创建出的新类型对象时,Copilot跟笨人说可以使用vector存储。于是笨人又继续追问vector的成员函数都有哪些,有什么作用,并要求Copilot写一个文件展示vector的各种语法和功能。最后笨人又询问了Copilot关于迭代器的知识以完成vector对象的迭代任务(这也是本算法中经常出现的重要逻辑)。于是笨人在任务编写过程中学习并训练到了关于vector的应用......
以上为笨人编写QM-Algorithm的一些心得体验。这是笨人第一次发帖子,如有任何问题,还请各位大神指教。(mol)
我为什么开始用 git worktree 管 AI 生成的代码
发布者:SweetGargamel
1 我为什么开始用 git worktree 管 AI 生成的代码
如果大家有用过Claude Code 或者 Codex 或者 Opencode之类的CLI的Coding工具的话,你会发现他不能像cursor那样选择性的apply或者reject代码,只能全盘接受他的所有修改(或者拒绝)
同时也没有什么很好的可视化的方式来看他修改了哪些代码(部分vscode插件可以做到预览,但是预览的也比较麻烦,可能就是这样类似的效果)
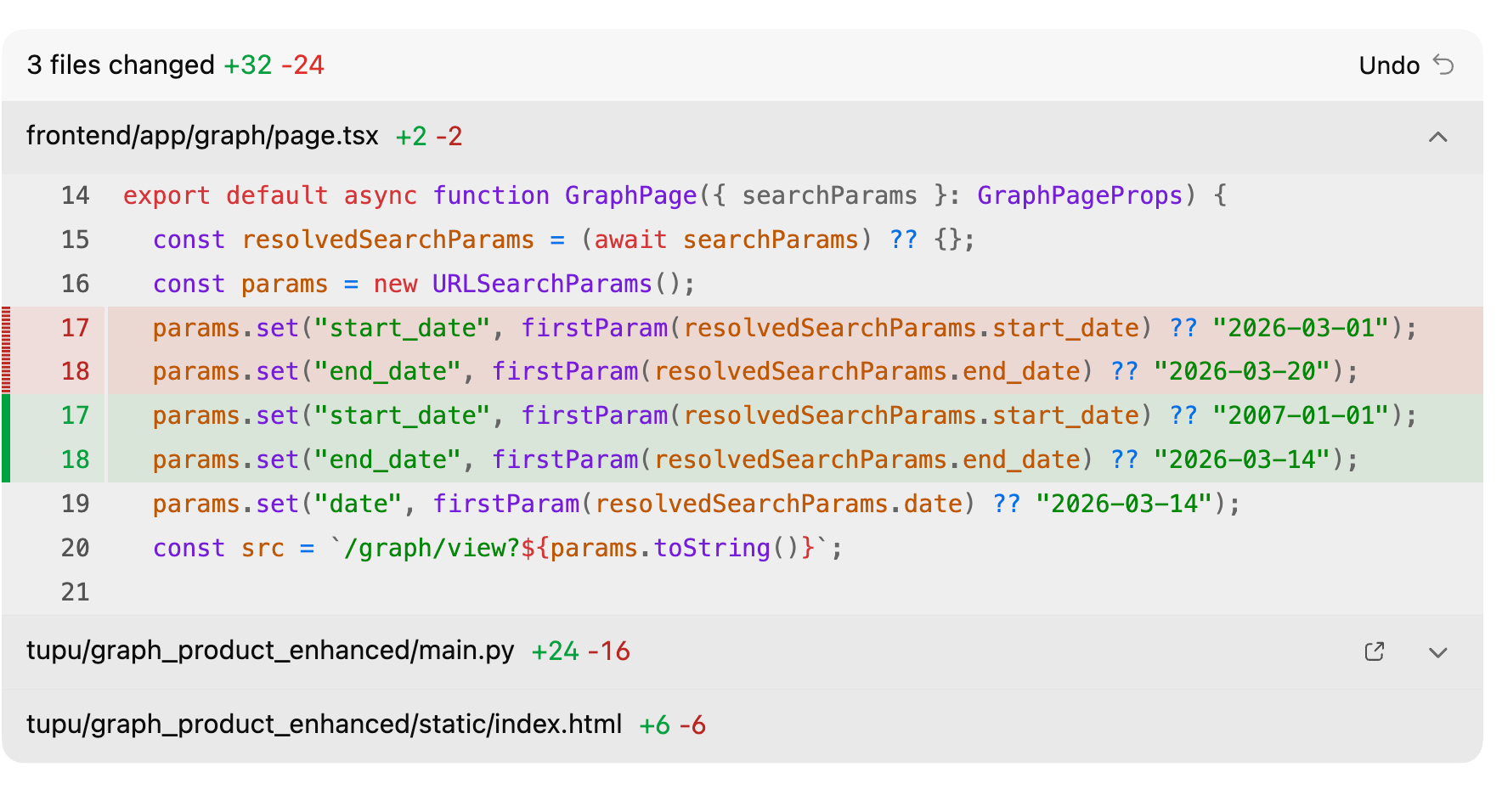 所以我开始尝试用git管理ai修改的代码。我可以用Pycharm自带的diff工具来查看不同的区别,同时选择性的选择应用。
所以我开始尝试用git管理ai修改的代码。我可以用Pycharm自带的diff工具来查看不同的区别,同时选择性的选择应用。
主工作区继续干主线,AI 的改动单独丢进一个 git worktree 里。
这个做法最直接的好处,不是”Git 更高级了”,而是脑子终于不用频繁换上下文了。Git 官方对 git worktree 的定义,本来就是 同一个仓库可以挂多个工作目录,并且同时检出不同分支 。这件事一旦放到日常开发里,体验上的变化其实非常朴素:主仓库保持稳定,AI 在旁边大胆试,试完我再决定哪些要吸收,哪些直接删掉。
这个思路其实和我原来笔记里的几句土话是同一个意思:以前切分支像灵魂出窍,现在更像肉身分离;主仓库是责任区,实验区只是候选方案区。
1.1 我以前为什么不爱切分支
以前我也不是不会用分支。
功能分支、修 bug 分支、临时实验分支,这些都很正常。问题不在 Git,问题在”切换”这件事本身。你正在写一半的代码、开着一堆终端、dev server 跑着、脑子里还挂着当前任务的上下文,这时候突然来一个 hotfix,或者突然想让 AI 试一个重构方案,你虽然知道”切个分支就行”,但整个人还是会断一下。
尤其是 AI 参与之后,这个断裂感更明显。
因为 AI 最擅长的是”快速给一个候选答案”,而不是替你承担最后的责任。它特别适合去写样板、铺测试、试重构、改脚手架、补胶水代码;但如果你让它直接在你当前主工作区里折腾,最后常见的结果不是它写错了,而是 你看不清了 。哪些文件是我刚改的,哪些是 AI 改的,哪些改动是为了验证思路,哪些改动其实根本不该留下来,全都搅在一起。
所以我后来不再问”AI 能不能直接帮我写”,我问的是: 怎么让 AI 的输出和我的责任边界分开。
git worktree 刚好就是干这个的。一个仓库,多开几个工作目录;主线在这边,实验在那边,谁也别打扰谁。(Git)
1.2 我现在怎么用
我现在的目录通常会长这样:
~/projects/my-saas/ # 主仓库,稳定开发 ~/projects/my-saas/worktrees/my-saas-ai/ # AI 草稿区 ~/projects/my-saas/worktrees/my-saas-hotfix/ # 紧急修复区
这个结构和我原来记下来的工作模式差不多:主仓库负责稳定开发,旁边挂几个不同用途的 worktree,像几个平行宇宙。
实际操作很简单。我一般会先把主线停在一个干净状态,然后给 AI 开一个短命分支,再单独挂一个 worktree 出去:
git switch main git commit -am "checkpoint before ai draft" git worktree add -b ai/draft-order-pricing ./worktrees/my-saas-ai main
git worktree add 本来就支持在指定目录创建一个新的工作树,也可以顺手基于某个起点新建分支。
做完以后,我通常会开两个 VS Code 窗口。
左边那个是主仓库,我继续写真正要进主线的东西。右边那个是 AI 草稿区,我让它在那里大胆尝试。它写坏了没关系,反正坏的是草稿区,不是我手上的主工作区。
这个感觉和”切分支”最大的差别,不在 Git 命令,而在人的注意力。切分支是逻辑切换;worktree 更像物理隔离。你看见的是两个目录,两个窗口,两套终端,两个开发上下文。脑子会轻松很多。
1.3 这个用法最爽的地方,不是 AI,而是 hotfix
一开始我以为自己会最常拿它干 AI 实验,后来发现真正让我离不开 worktree 的,反而是紧急修 bug。
场景很常见:你正在主仓库写新功能,写到一半,线上突然炸了。以前我的做法一般是先 stash,或者硬切分支过去修,修完再切回来。技术上当然也能干,但节奏会断,编辑器状态会断,终端上下文也会断。
现在我直接开一个 hotfix worktree:
git worktree add -b hotfix/critical-bug ./worktrees/my-saas-hotfix main cd ./worktrees/my-saas-hotfix
然后在这个目录里修、提、推,修完以后把它关掉。主仓库那边原封不动,dev server 继续跑,写到一半的文件还停在那儿,我回来接着写就行。
我原来在笔记里写过一句话:以前切分支像”灵魂出窍”,现在是”肉身分离”。 这句话虽然土,但很准。因为 worktree 真正解决的不是 Git 技巧问题,而是上下文切换成本。
1.4 用命令行的方式审查ai的代码
你可以这样看差异
git diff main...ai/draft-order-pricing
或者只看某个文件:
git diff main...ai/draft-order-pricing -- src/domain/order_pricing.ts
你会发现,一旦 AI 的改动被隔离到一个独立 worktree 里,review 这件事会轻松很多。因为你面对的不是一坨混在当前工作区里的脏改动,而是一个清清楚楚的”候选答案”。
如果我觉得这份候选答案整体还行,但不想保留它那个分支历史,我会直接 squash 进当前分支:
git switch main git merge --squash ai/draft-order-pricing
这个方式特别适合 AI 协作。因为 AI 的分支历史很多时候没有保留价值,我真正想要的只是”把这个候选实现铺到眼前,然后我自己再挑、再改、再提交”。
当然,如果你是大面积的修改,命令行看起来可能就有点不舒服了
1.5 如何不开pull Request自己Review AI代码
1.5.1 方法A
让AI在worktree写完后commit到 ai-fix 分支上【或者我们可以直接开一个worktree叫ai_playground然后每次ai写完了先Review和merge,然后再把 ai_fix 直接挪到merge后的结果上即可。这样就是开两个Vscode窗口就可以了】,然后用
# 1) 切到目标分支 main
git switch main
# 2) 确保工作区干净(很重要)
git status
# 3) 合并 ai-fix,但不提交
# --no-ff表示不用fastforward
git merge --no-commit --no-ff ai-fix
# 或者使用 把 ai-fix 的全部差异压扁应用到当前分支,但不提交
git merge --squash ai-fix
接下来打开vscode的change面板会有两个change,左侧是 HEAD 提交(也就是我们在 git merge --no-commit --no-ff ai-fix 前的提交)
这里会分 staged change 【在staged区】和普通 change 【在working区】,这里我点开的是普通的 change 。中间的按钮你可以revert或者把他staged了
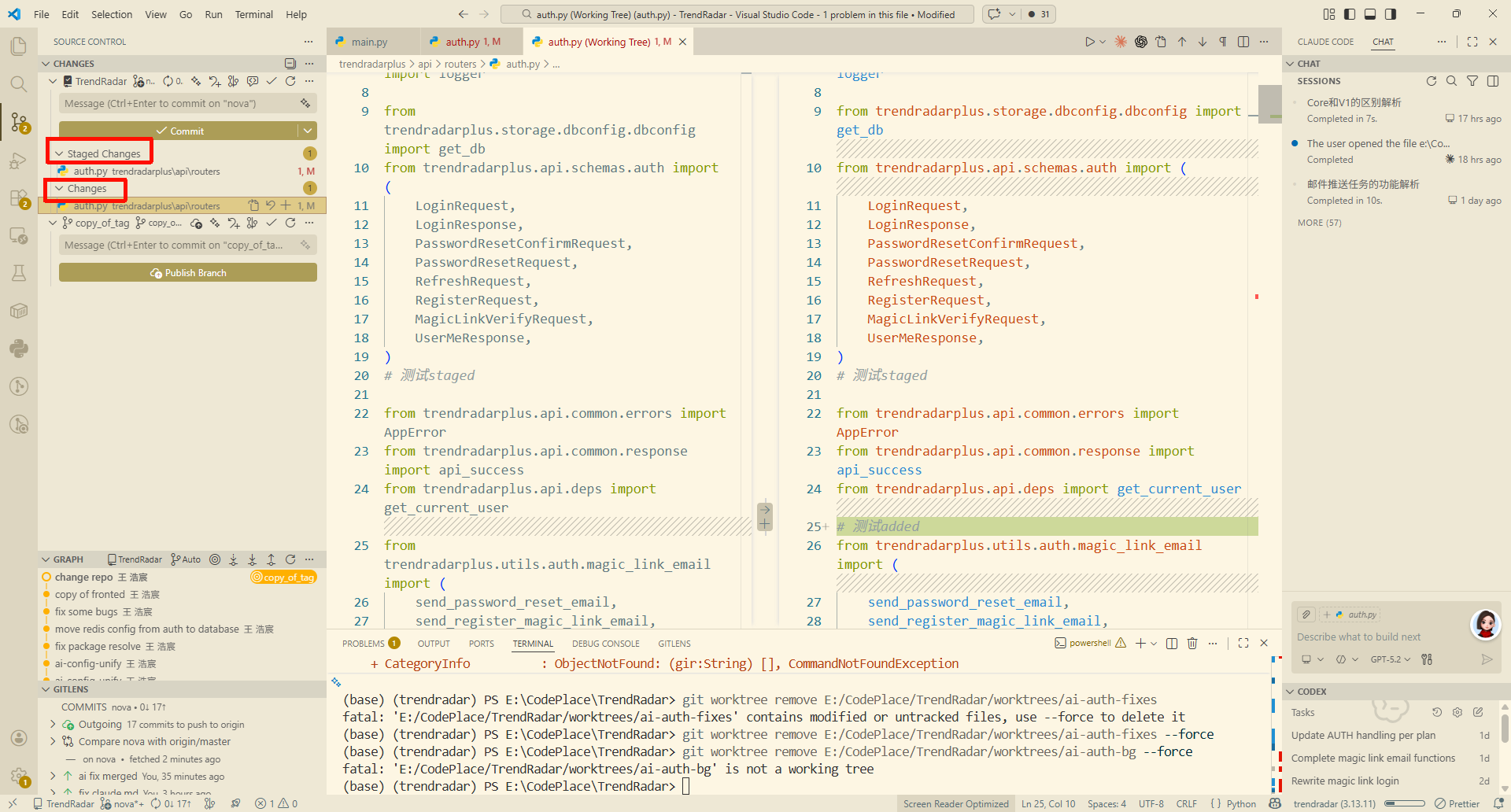 【刚跑完上面的命令一般只会有
【刚跑完上面的命令一般只会有 staged change 我们可以参考图二取消`staged】
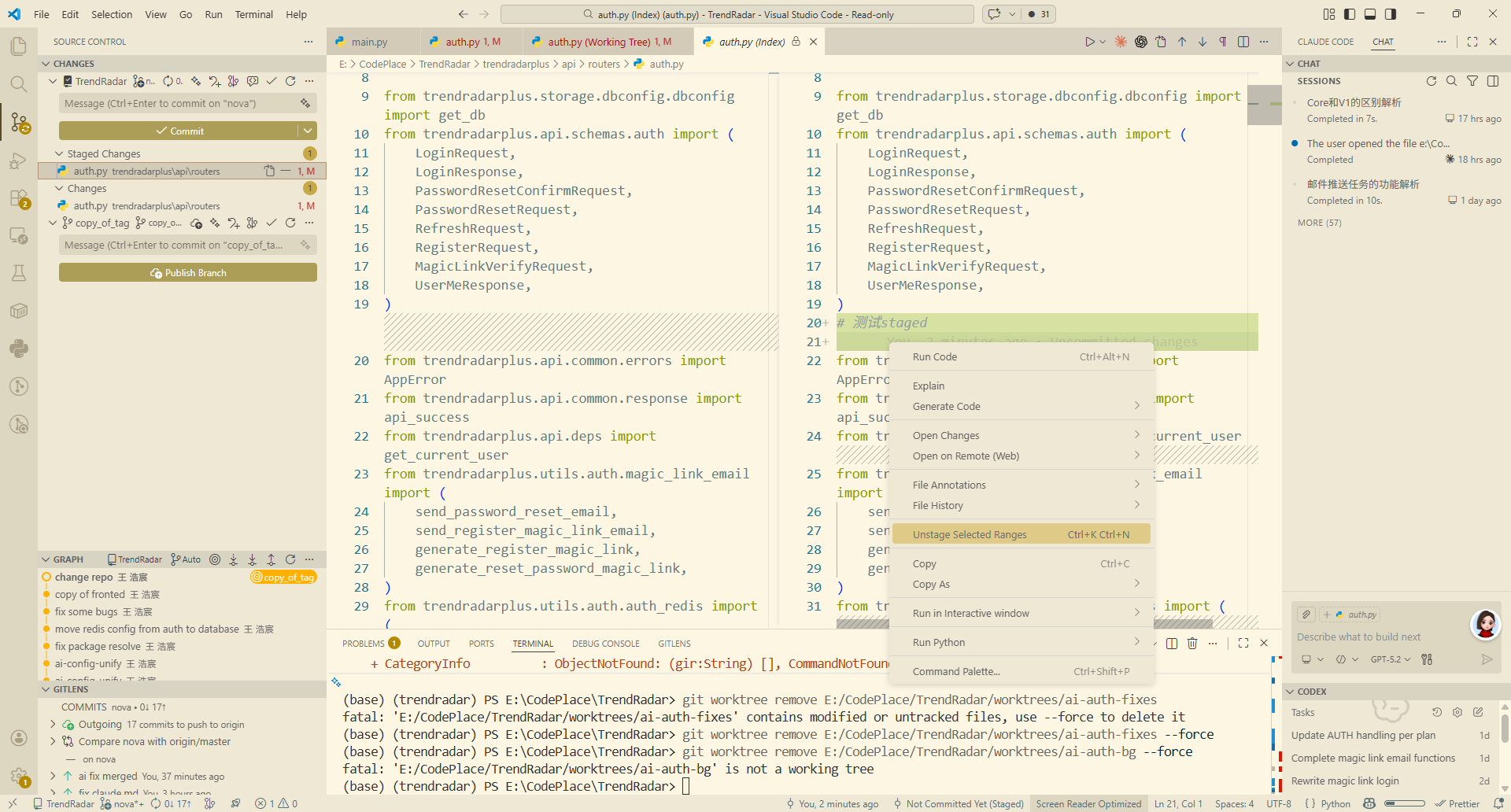 在
在 staged 里面,我们能做的比较少,一般只能取消 staged ,但是如果我们放到普通的 change 里面就可以直接对文件进行编辑。
可以用这个命令一键全部从 stage 覆盖到 working area
git restore . # 注意,--staged是用HEAD提交来覆盖index区域
1.6 几个我踩过的坑
1.6.1 1)别把实验分支养太久
AI 草稿分支这东西,最适合短命。
它的价值是”候选方案”,不是长期维护。你今天让它试一个重构,明天让它铺一层测试,后天再让它改个脚本,这些都适合用临时分支和临时 worktree 做。事完删掉,世界清净。
我现在会定期清理:
git worktree list git worktree remove ./worktrees/my-saas-ai git branch -D ai/draft-order-pricing git worktree prune
git worktree remove 和 git worktree prune 都是官方支持的清理方式。(Git)
1.6.2 2)别在两个 worktree 里同时改同一块东西
虽然是多个目录,但本质上它们还是挂在同一个仓库上。官方文档也明确说了,主工作树之外还可以有零个或多个 linked working tree。(Git)
所以最怕的不是”不会用”,而是”乱用”:
- 主仓库改一半
- AI worktree 也在改同一个文件
- hotfix worktree 又顺手改了一下相关逻辑
最后不是 Git 出问题,是你自己已经不知道哪份改动该信谁了。
我的经验很简单:一块逻辑同一时刻只让一个 worktree 负责。主仓库负责主线,AI 区负责提议,hotfix 区只干救火。井水不犯河水,事情就会简单很多。
论坛汉化小更新:Issue #31 已解决
发布者:小核桃
大家下午好!
最近顺手把 NJUTIC 论坛(tic-forum)的 UI 给汉化了。
之前那个全英文界面确实有点儿违和,看着不够顺眼。趁着这两天有空,我把涉及到 Navbar、PostCard 还有各种交互文案的 12 个核心文件都过了一遍。现在全站已经基本实现中文化适配了。
中间稍微折腾了一下仓库权限和 PR 关联(GitHub 的 patch 分支逻辑确实有点绕),不过好在小许给开了 Org 权限,最后 PR #33 已经顺利 Merge 了。
汉化后的界面现在已经上线,大家登录论坛就能看到。如果在使用中发现哪里的翻译不够地道,或者排版还有瑕疵,欢迎直接去仓库开 Issue 指正。
希望大家可以合作共建一个更完善的NJUTIC论坛!
从一条 main 用到底,到理解多人开发的协作逻辑
发布者:selflo
# 从一条 `main` 用到底,到理解多人开发的协作逻辑
很多人刚开始写代码时,流程其实都很简单:一条 `main` 用到底,有功能就直接写,有 bug 就直接改。 在单人开发阶段,这种方式通常没什么问题。项目只有一个维护者,改了什么、影响到哪里、后面准备怎么收尾,基本都在掌控之中。
但一旦进入多人协作,事情就不一样了。 开发不再只是“把功能做完”,还要考虑改动是否清晰、是否方便 review、会不会影响别人,以及出了问题之后能不能快速追踪。
也是在这个过程中,才会慢慢意识到:多人开发真正需要转变的,不只是 Git 的用法,而是对“开发流程”本身的理解。
---
## 单人开发时,为什么一条main也能工作
一条main用到底,本身并不是什么错误习惯。
在个人项目、课程作业或者小型 demo 里,这种方式反而很直接:
- 不需要切分支
- 不需要提 PR
- 不需要等待 review
- 所有上下文都集中在一个人身上
流程足够轻,开发节奏自然也更快。 所以在单人场景下,关注点往往是“尽快做完”,而不是“如何协作”。
但这里其实有一个隐含前提:只有一个人在维护这份代码。

{kind=link}
---
## 多人开发时,主分支就不再只是“自己的工作台”
进入多人协作之后,`main` 的角色会发生变化。
单人开发时,`main` 更像当前工作的延长线,想到什么就可以直接改。 但在多人开发里,`main` 往往意味着团队共享的主线,它最好保持稳定、清晰、可追踪,很多时候甚至还承担着“随时可发布”的职责。
这时候如果还像以前一样直接在 `main` 上开发,就很容易出现一连串问题:
* 不同人的改动互相影响 * 写到一半的代码提前进入主线 * 无关改动混在一起,难以 review * 后续排查问题时,提交历史十分混乱 * 合并时冲突集中爆发
所以多人开发里最先变化的,其实不是写代码的动作,而是对主分支的认知。 **它不再只是某个人的工作台,而是整个团队共享的主干。**
---
## 分支的意义,是把改动隔离成清晰的单元
既然 `main` 需要保持稳定,那么最基本的做法就是:**从 `main` 拉出自己的分支,在分支上完成当前任务。**
比如要做一个登录功能,可以先切出一条分支:
```bash git checkout -b feature/user-login ```
表面上看,这只是“多开一条线”; 但实际上,它真正解决的是**改动隔离**的问题。
在分支上开发,意味着:
* 未完成的功能不会直接影响主线 * 改动范围更集中,方便 review * 方案如果推翻,可以直接放弃这条分支 * 每个人都能在相对独立的空间里推进自己的任务
所以分支不是为了让 Git 看起来更复杂,而是为了让协作更可控。 它本质上是在回答一个问题:**这次改动,能不能先和团队主线隔离开来,再以清晰的形式合并回去。**

{kind=link}
---
## PR 的价值,不只是“申请合并”
刚接触多人开发时,很容易把 PR 理解成一个固定流程:代码写完,发起 PR,等别人看过,再 merge。
但 PR 真正的价值,其实远不止“申请合并”。 它更像是在告诉团队:**这里有一批边界清晰的改动,值得被一起看清楚。**
一个好的 PR,至少有三层作用。
第一,它明确了改动边界。 review 的人不需要猜“最近到底改了什么”,因为这次变更已经被打包成了一个清晰的单元。
第二,它给讨论提供了上下文。 问题可以直接落在具体文件、具体代码行上,而不是停留在笼统的描述里。
第三,它会沉淀协作过程。 为什么这么改、为什么不用另一种方案、哪些边界已经考虑过,这些信息往往都会留在 PR 的讨论记录里。
所以 PR 并不只是“把代码合进去”,而是让团队在进入主线之前,先把这次改动的边界、质量和影响面看清楚。
---
## Code Review 不是挑刺,而是在提前暴露问题
Review 很容易让人产生一种“被检查”的感觉,尤其是之前一直习惯单人开发时。 但在团队协作里,review 更重要的意义其实是:**尽可能把问题挡在 merge 之前。**
很多问题如果能在进入主分支之前发现,处理成本通常很低; 但如果已经合进主线,甚至进入测试环境或线上环境,再返工就会麻烦很多。
Review 常见会发现的问题包括:
* 逻辑漏洞 * 边界情况遗漏 * 命名不清晰 * 抽象层次不合理 * 改动影响面超出预期 * 测试覆盖不足
除此之外,review 还有一个很容易被低估的作用:**帮助团队逐渐形成一致的工程习惯。**
单人开发时,风格统一几乎是天然成立的。 但在多人协作中,如果没有 review 这种机制,项目很容易在命名、结构、提交习惯上越走越散,最后谁都能看懂一点,但谁都看不顺手。

{kind=link}
---
## 真正需要改变的,不只是 Git 命令,而是协作视角
多人开发当然离不开 Git,但比起记住多少命令,更重要的是先接受一个事实:
> 每一次改动,都不再只是“我把功能做完了”,而是“我提交了一个需要被团队理解、评估和接纳的变更单元”。
一旦换到这个视角,很多规范都会变得很自然。
为什么要切分支? 因为需要隔离改动。
为什么要控制 PR 大小? 因为过大的改动很难 review。
为什么要规范 commit 命名? 因为提交历史本来就是团队协作的一部分。
为什么不要把修 bug、重构、顺手改样式混成一坨? 因为这样既不利于 review,也不利于后续追踪和回滚。
很多时候,这些看起来像“流程要求”的东西,本质上都在做同一件事:**降低协作摩擦。**
---
## 分支命名和 commit 命名,看起来是细节,其实很重要
单人开发时,分支名和 commit message 往往怎么顺手怎么来。 像 `test`、`tmp`、`update`、`fix bug` 这种名字,自己当下未必看不懂。
但放到多人协作里,这种命名方式的信息量就太低了。 它可能在提交当下还能勉强理解,过几周再回头看,基本只剩下“好像改过东西”,却看不出到底改了什么。
### 分支命名
比较常见的分支命名方式有:
* `feature/xxx` * `fix/xxx` * `refactor/xxx` * `docs/xxx` * `chore/xxx`
例如:
* `feature/user-login` * `fix/order-timeout` * `docs/api-usage`
这样的好处很直接:别人看到分支名时,几乎立刻就能知道这条分支在做什么。
### commit 命名
提交记录本质上是项目历史的一部分。 如果 commit message 太随意,后续排查问题会很痛苦。
像下面这种方式就清楚很多:
```text feat: add user login API fix: handle null response in order service docs: update setup instructions refactor: simplify auth middleware test: add unit tests for payment module ```
规范命名的意义,不只是“看起来整齐”,而是让历史记录真正变得可读、可追踪、可回溯。

{kind=link}
---
## 一个比较实用的多人开发流程
如果用最常见的方式来概括,一个比较实用的多人开发流程大概是这样:
### 1. 从 `main` 拉取最新代码
```bash git checkout main git pull origin main ```
### 2. 为当前任务创建独立分支
```bash git checkout -b feature/user-profile ```
### 3. 在分支上开发,并保持提交清晰
```bash git add . git commit -m "feat: add user profile page" ```
### 4. 推送远程并发起 PR
```bash git push origin feature/user-profile ```
### 5. 接受 review,并继续修改
### 6. review 通过后,再合并回 `main`
这套流程看起来比单人开发麻烦一些, 但换来的,是更清晰的改动边界、更低的冲突成本,以及更稳定的团队协作体验。
换句话说,它确实增加了一点流程成本,但也显著减少了后续的沟通成本、排查成本和返工成本。

{kind=link}
---
## 结语
从单人开发转向多人开发,表面上看是在学习分支、PR 和 review; 但更深一层,其实是在适应一种新的工程思维。
单人开发更关注“怎么尽快做完”; 多人开发则更强调“怎么让改动以一种清晰、可协作、可追踪的方式进入项目”。
所以真正需要改变的,往往不是某条 Git 命令怎么写, 而是开始意识到:**写代码这件事,从来不只是把功能实现出来,还包括如何让它被他人理解、接住,并长期维护下去。**
hello
发布者:asimov
hello,njutic!
hello world
发布者:Insouciant21
hh
114514
发布者:admin
1919810
欢迎!
发布者:selflo
目前论坛还在开发和测试简短,有新功能的想法或者发现了bug可以来https://github.com/NJU-TIC/forum/issues 来反馈!
(发现新bug,插入url后会导致该行后续字符均被识别为url,只有换行后才正常)
content test
发布者:selflo
H1
H2
H3
some~~ ~~content
code:
无高亮,为bug
#include <iostream>
using namespace std;
int main() {
cout << "hello world!" << endl;
return 0;
}
URL
无高亮,为bug
https://images.selflo06.xyz/GeminiBalance/8.jpg
Image:

List
- 1
- 2
- 3
- 1
- 2
- 3
cover image test
发布者:selflo
cover image test
content image test
发布者:selflo
111
发布者:selflo
111
First Post
发布者:selflo
test
